A sound is recorded by making a measurement of the amplitude of the sound at regular intervals which are defined by the "sample rate". The act of taking the measurement is often called "sampling" and each measurement unit is called a "sample". A file which contains samples is often called a "sound sample" or "audio sample".
The "sample rate" defines the rate/frequency at which the measurements are taken. The higher the sample rate, the faster the measurements are taken, and the lower the sample rate, the slower the measurements are taken. The sample rate is described by the "Hz" unit of measurement. The "Hz" unit of measurement means "per second". Therefore, a sample rate of 44010Hz means 44010 measurements are taken each second (this is one measurement every 1/44010 th of a second).
If the "sample rate" is too low, then changes in the sound which occur between each measurement will not be measured. Therefore the faster the measurements are taken, the more accurate the recording will be, and therefore the higher the quality of sound that can be recorded.
It is worth noting that at high sample rates, because there are many more measurements taken, the resulting size of the file (containing the audio data) can be large.
A "sample" which uses 8-bits for storage can represent 256 distinct amplitude levels and a sample which uses 16-bits for storage can describe 65535 distinct amplitude levels. The higher the number of bits used by each sample for storage, the larger the range of distinct amplitude levels that can be represented. Therefore, the higher the number of bits used by each sample for storage, the higher the quality of sound that can be recorded.
All modern sound cards should support 8-bit and 16-bit samples and sample rates of 22050Hz and 44100Hz.
Some sound cards will support a greater range of recording rates which can be lower and higher than these values.
For samp2cdt you should save the file as "PCM" ("Pulse Code Modulation"). This is a uncompressed, unencoded storage representation. Each sample is a single measurement of the amplitude of the sound taken at a measurement point in time.
Other representations such as "ADPCM" ("Amplitude Delta Pulse Code Modulation"), encode or compress the data to reduce the size of the audio file. Samp2cdt can't understand these representations, so please use "PCM" only.
[Fig 1. An amplitude/time graph showing the waveform of the original sound]
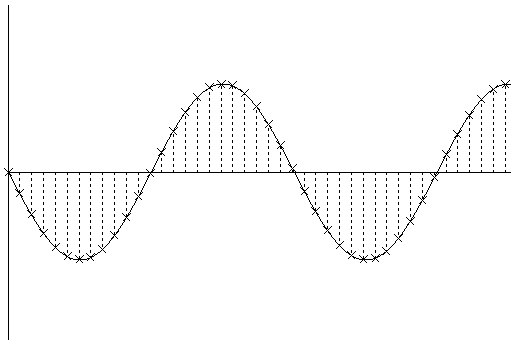
[Fig 2. An amplitude/time graph showing the waveform of the original sound. The crosses indicate the amplitude measured at each sample time and the dotted lines indicate the the time of each measurement. The duration of time between each dotted line, defined by the sample rate, is equal to the duration of a sample. From this it can be seen that each sample has a finite and equal duration.
![[Image of the amplitude/time graph for the original waveform. The waveform generated by sampling is indicated by a dotted
line]](wave3.png)
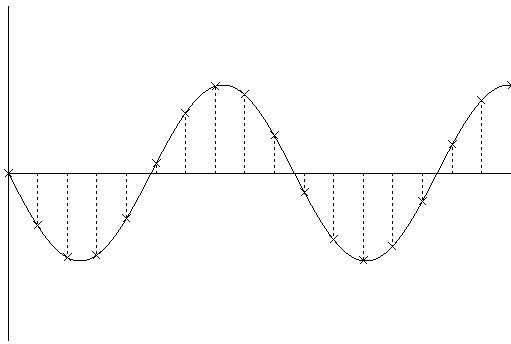
[Fig 3. An amplitude/time graph showing the waveform of the original sound. As in Fig 2, the crosses indicate the amplitude measured at each sample time. The dotted line shows the waveform generated by sampling. The final value of each sample is defined to be the amplitude measured at the time of measurement.
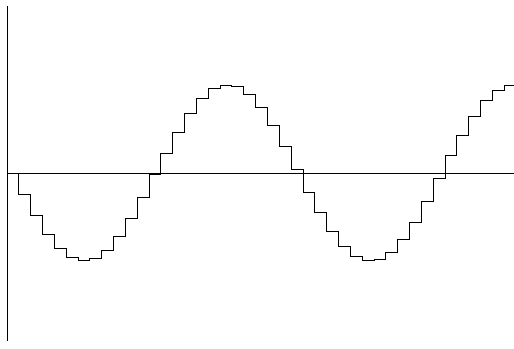
[Fig 4. An amplitude/time graph showing the sampled waveform. This waveform was generated at a high sample rate, and therefore the resulting waveform has a shape which is similar to the original. This waveform is the type you can see in a audio recording program like Goldwave.
[Fig 5. An amplitude/time graph showing the waveform of the original sound. As in Fig 2, this graph shows the amplitude of each measurement, and the dotted line indicates the time of measurement. This graph was created using a low sample rate. Notice that the time between each measurement is longer compared to Fig 2.
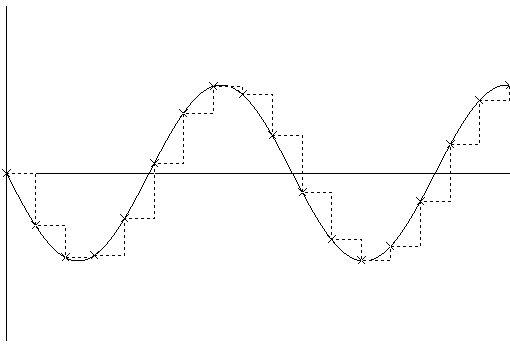
[Fig 6. An amplitude/time graph showing the waveform of the original sound. As in Fig 3, the crosses indicate the amplitude measured at each sample time, and the dotted line shows the waveform generated by sampling. This graph shows the resulting waveform generated using a low sample rate.
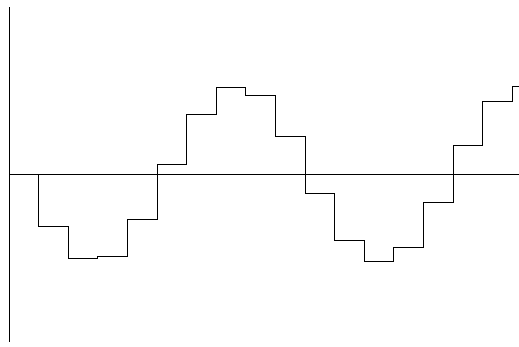
[Fig 7. An amplitude/time graph showing the sampled waveform. This waveform was generated at a low sample rate, and therefore the resulting waveform is much more coarse compared to Fig 4. Notice that although the general shape is similar to the original waveform, and much of the smoothness is is lost between the time of each measurement. The loss of smoothness also means loss of information since this waveform is not the same as the original. If you compare this graph against Fig 4 then you will see that the lower the sample rate, the more information is lost. The higher the sample rate, the less information is lost. Therefore, to record a sound, it is best to use a high sample rate]
Notes:
i.e. to record a sound of 3000Hz, you must record using 6000Hz.
If you use a lower frequency (e.g. 5000Hz), then the sound is not recorded accuratly.
Most Amstrad loaders are between 300 to 2500Hz, therefore you should use a recording sample rate of at least 5000Hz. It is recommended to use one of the "common" sample rates. e.g. 22050Hz (22Khz) or 44100Hz (44.1Khz)
Both methods can represent the same data, so there is no advantage to using either. The original reason for the two methods is due to the original method to playback the sound. Modern sound cards can play both methods of data storage.
When the writing of a program is completed a "master" cassette is created. This cassette contains a audio representation of the computer data.
The master cassette is then duplicated, using a machine, onto many blank cassettes. These cassettes are packaged with instructions and distributed.
It is also easy to make a copy of a cassette if you have a twin cassette system, where one cassette unit will play the sound and the other will record. A first generation copy taken from a original cassette could be considered a copy of a copy of the master cassette.
Each time a cassette is copied however, additional noise may be introduced into the copied version. This noise is a mixture of noise from the original, and noise created by the machine making the copy. Therefore the sound on any cassette contains a mixture of noise and the sound of the computer data.
A loader on the computer must therefore be able to identify the actual sound of the data from other sounds that are on the cassette. If it can't do this, then there will be loading errors.
If you are transfering a cassette using samp2cdt, then you are advised to use an original (i.e. a cassette created directly from a master cassette), or a first generation copy (i.e. a cassette copied from an original).
A "loader" is the name given to a program that reads data from cassette into the computer memory.
There is a "system" loader which is built into the Amstrad CPC ROM. This loader is activated when the computer is in cassette mode (note 1), and it can only understand one specific computer audio sound, the audio sound of the Amstrad CPC system data-blocks.
To read other loading systems (e.g. a fast-loader), there must be a program on the cassette (a "pre-loader" or "boot loader" or sometimes refered to as "loader"), stored using the Amstrad CPC system loader, which when executed will be able to understand and load fast-loader data.
This loader program is usually stored immediatly before any fast-loader blocks, and takes over from the system loader to load the remaining fast-loader blocks.
|program for fast-loader| |fast-loader block(s)|
So when a cassette is loaded the following occurs:
Notes:
You can test if the computer is operating in cassette mode by typing RUN". If you see "Press PLAY then any key", then the computer is operating in cassette mode. If there is an error, then the computer is not operating in cassette mode.
The audio from the cassette is read from a cassette player through the Amstrad's cassette electronics.
The Amstrad's cassette electronics converts the amplitude of the sound (a analogue signal) into a "0" or "1" measurement (a digital signal). This measurement can then be read from bit 7 of port B of the PPI 8255 IC.
![[Picture showing the conversion process]](conv.png)
[Fig 8. This image shows the conversion of the audio waveform from the cassette into the digital representation by the Amstrad's cassette electronics. i.e. audio waveform (on cassette) -> Amstrad's cassette electronics -> 0 and 1 measurements]
The resulting measurements can be read using the following Z80 instructions:
ld b,&f5 ;; I/O port address for PPI 8255 port B ;; (PPI 8255 port B is operating as input.) in a,(c) ;; read port B inputs and %10000000 ;; isolate bit 7 which contains the measurement.
This measurement is *not* the actual state of a data-bit, but represents a low ("0") or high amplitude ("1"). In this document, the value of this measurement will be refered to as a "high" ("1") or "low" ("0") level.
Notes:
samp2cdt uses a crude method to perform this conversion.
For a 8-bit signed sample:
A waveform is written to cassette using bit 5 of port C of the 8255 PPI IC. The waveform can only be defined by a high or low level, defined by the state of bit 5, which is then converted by the Amstrad's cassette electronics into a final output amplitude which is recorded onto cassette.
A high level can be written using the following Z80 instructions:
ld b,&f6 ;; I/O port address for PPI 8255 port C ;; (PPI 8255 port C is operating as output.) set 5,a ;; set cassette write output to high level out (c),a ;; output level
A low level can be written using the following Z80 instructions:
ld b,&f6 ;; I/O port address for PPI 8255 port C ;; (PPI 8255 port C is operating as output.) res 5,a ;; set cassette write output to low level out (c),a ;; output level
The amplitude of the output waveform is not amplified, therefore if you wish to record the cassette audio direct from an Amstrad you will need to amplify the waveform.
If the state of bit 5 is changed at a fixed frequency, then the graph of the state of bit 5 over time will be a square wave. However, the resulting audio written on the cassette will not be a perfect square wave because nature will attempt to convert the waveform into a sine wave.
Every loading system on the Amstrad uses a serial bit-stream. i.e. a single bit of information is read at a time.
This serial bit-stream is grouped into blocks of audio sound.
Every loading system uses a basic structure to describe each audio block in the following order:
|pilot|sync|data|trailer|
This is constructed from a repeated waveform often with a fixed number of repetitions defined by the loading system.
The shape of the waveform is known by the loader program and this is used to identify the pilot waveform from other waveforms that may be present (e.g. noise).
The pilot is often long, so that the loader doesn't need to see the start of the pilot waveform in order to load the block.
The loader program will test the incoming waveform, checking it against the parameters defined for the pilot, before the waveform is accepted as the pilot waveform. (e.g. the number of repetitions must be some defined minimum value). The incoming waveform must fall within these specifications otherwise the waveform is not accepted as a pilot waveform.
The first element of the data may be a marker or id which may, for example, indicate the type of data in the block or the number of the block.
The remaining bits will define the data and zero or more checksums.
The whole data may consist of a single block with a single location and length (e.g. one block for a screen another for data), or multiple blocks each with their own location and length. (e.g. one block for screen and data)
The location and lengths of the blocks may be in the data stream itself, or they may be in a preceeding block, or may be hard-coded into the loader program.
The exact definition of the loading systems's audio waveform is defined by the loader program.
samp2cdt has a number of decoder algorithms which recognises the audio waveform of various loading systems. These decoders read the waveform using a similar method to the loader program itself. These decoders have been created by examining the instructions of each loader program and the graph of the waveform in a sound recording package.
A "Checksum" is used to verify the loaded data.
A Checksum is the result of the "checksum calculation" made on a block of data. The actual calculation can be different depending on the method chosen.
There are two "Checksum"s.
This is the result of the "checksum calculation" calculated from the correct data. This is then stored with the data (e.g. before or after the data) when the master cassette is created.
This is the result of the "checksum calculation" calculated from the data read from the cassette. After the calculation is complete it is compared against the stored checksum.
The stored and calculated "Checksums" are initialised with the same initial value and calculated using the same algorithm. Therefore, if the stored checksum matches the calculated checksum, it is assumed that the loaded data is identical to the original data. The data is verified to be correct.
If the stored checksum doesn't match the calculated checksum, then there has been a error. One or more bit's of data is incorrect. The checksum is designed to detect errors only, and often it is not possible to know which bit or bits of data is incorrect and in this case it is not often possible to correct the errors to reproduce the correct data.
A loader which has a checksum therefore is better than a loader that doesn't have a checksum, because the checksum will verify that the data is correct or incorrect.
With a loader which doesn't have a checksum, you have no way to verify the data, and therefore you can't guarantee that the data is identical to the original.
In this case, the only way to test that the data is correct is to make multiple transfers of the program and test each thoroughly (e.g. if the program is a game, you would play the game to the end), checking for graphic corruption and bugs. If all of the transfers operate the same, then you can assume that the data is correct.
There are numerous Audio file formats, each of which can store audio, but each has it's own structures and representation for the data.
The "format" of a file describes the internal structure, order and encoding of the data within the file.
Here is a list of the audio file formats supported by samp2cdt: